Uji normalitas data dapat dilakukan dengan beberapa cara antara lain
- Visual dengan grafik salah satunya histogram
- Uji statistik seperti Kolmogorov-Smirnov atau Shapiro-Wilk
Berikut akan dilakukan uji normalitas atas data konsumsi bir tahun 2010. Data diambil dari https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv dengan pengubahan nama variabel menjadi lebih singkat.
Uji normalitas dengan histogram
Histogramnya
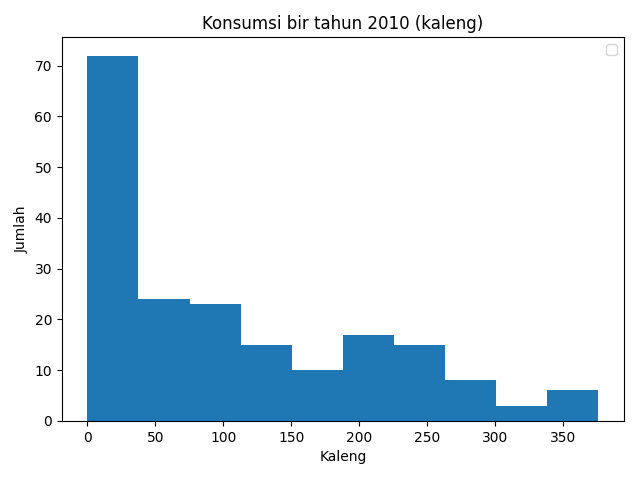
Dari histogram tersebut tampak dengan jelas bahwa histogram tidak simetris dengan skewness positif. Maka dapat disimpulkan data konsumsi bir ini tidak mengikuti distribusi normal.
Uji Kolmogorov-Smirnov dan Shapiro-Wilk
Misalkan ditentukan level signifikansi 5% atau 0.05. Hipotesisnya adalah:
- H0: data tidak sesuai dengan distribusi normal
- HA: data sesuai dengan distribusi normal
#!/usr/bin/python3
import pandas as pd
from scipy.stats import kstest, shapiro
# sumber data https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv
# dengan editing header variabel
alkohol = pd.read_csv("../dataset/drinks.csv")
# Uji Kolmogorov-Smirnov (kstest) dan Uji Shapiro-Wilk (shapiro)
ksdata = kstest(alkohol['beer_servings'], 'norm')
swdata = shapiro(alkohol['beer_servings'])
print(ksdata)
print(swdata)
Hasilnya
KstestResult(statistic=0.8950231589631885, pvalue=2.5964374859935023e-189)
ShapiroResult(statistic=0.8826810121536255, pvalue=3.9431170134607285e-11)
Dari hasil tersebut, kedua uji menunjukkan pvalue kurang dari 0.05. Sehingga H0 bisa diterima (data tidak sesuai dengan distribusi normal).