PSPP merupakan software statistika yang open source, ringan tetapi sangat fungsional dan powerful. Ringan karena installer-nya hanya beberapa MB. Jauh lebih kecil daripada software sejenis yang proprietary. Fungsional dan powerful karena berbagai analisis dapat dilakukan dengan PSPP.
PSPP bisa dijalankan dengan tampilan text ataupun grafis. Uktuk memulai pspp tampilan text
Untuk membuka file, pada PSPP prompt
PSPP> get file='tulis-nama-filenya yang berekstensi sav'.
Bagian dalam tanda kutip adalah file yang akan dibuka.
Uji normalitas data dapat dilakukan dengan beberapa cara antara lain
- Visual dengan grafik salah satunya histogram
- Uji statistik seperti Kolmogorov-Smirnov atau Shapiro-Wilk
Berikut akan dilakukan uji normalitas atas data konsumsi bir tahun 2010. Data diambil dari https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv dengan pengubahan nama variabel menjadi lebih singkat.
Uji normalitas dengan histogram
Histogramnya
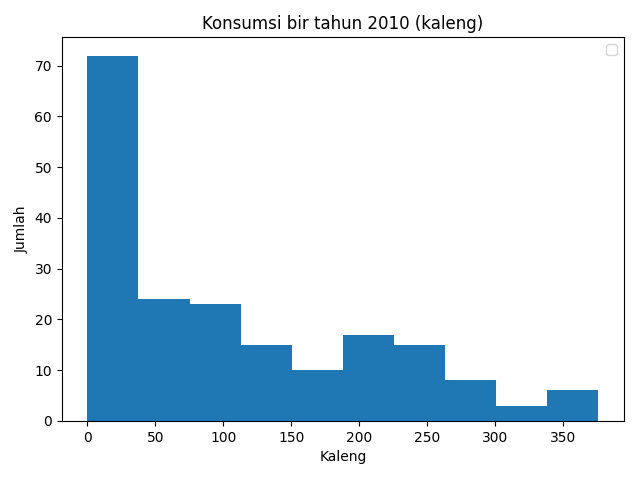
Dari histogram tersebut tampak dengan jelas bahwa histogram tidak simetris dengan skewness positif. Maka dapat disimpulkan data konsumsi bir ini tidak mengikuti distribusi normal.
Untuk membuat histogram dengan python dibutuhkan library pandas dan matplotlib dengan fungsi .hist() dan rangkaiannya seperti contoh histogram konsumsi bir berikut:
#!/usr/bin/python3
import pandas as pd
import matplotlib.pyplot as plt
# sumber data https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv
# dengan editing header variabel
alkohol = pd.read_csv("../dataset/drinks.csv")
# histogram
plt.hist(x='beer_servings', data=alkohol)
plt.xlabel('Kaleng')
plt.ylabel('Jumlah')
plt.title('Konsumsi bir tahun 2010 (kaleng)')
plt.tight_layout()
plt.show()
Hasilnya:
Misalkan akan dicari berapa median konsumsi alkohol perkapita? Jawabannya bisa diketahui dengan menggunakan fungsi describe() atau median() yang dimiliki pandas.
#!/usr/bin/env python3
import pandas as pd
# sumber data https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv
# dengan editing header variabel
data = pd.read_csv("../dataset/drinks.csv")
# median
print('median konsumsi bir adalah ',data['beer_servings'].median(),'kaleng')
print('median konsumsi spirit adalah ', data['spirit_servings'].median())
print('median konsumsi anggur adalah ', data['wine_servings'].median(), 'gelas')
print('median konsumsi alkohol murni adalah ', data['pure_alcohol'].median(), 'liter')
Misalkan akan dicari berapa rerata konsumsi alkohol perkapita? Jawabannya bisa diketahui dengan menggunakan fungsi describe() atau mean() yang dimiliki pandas.
#!/usr/bin/env python3
import pandas as pd
# sumber data https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv
# dengan editing header variabel
data = pd.read_csv("../dataset/drinks.csv")
# mean
print('rerata konsumsi bir adalah ',data['beer_servings'].mean(),'kaleng')
print('rerata konsumsi spirit adalah ', data['spirit_servings'].mean())
print('rerata konsumsi anggur adalah ', data['wine_servings'].mean(), 'gelas')
print('rerata konsumsi alkohol murni adalah ', data['pure_alcohol'].mean(), 'liter')
Untuk menampilkan statistik deskriptif suatu data, bisa menggunakan fungsi describe() dari library yang dimiliki python yaitu pandas.
Berikut ini akan ditampilkan deskripsi data konsumsi alkohol dunia. Sumber data : https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv
Data tersebut memuat konsumsi alkohol perkapita dari 193 negara. Ada 4 variabel yaitu :
- beer_servings (konsumsi bir yang dinyatakan dalam kaleng)
- spirit_servings (konsumsi minuman beralkohol spirit; maaf, variabel ini masih belum penulis pahami sepenuhnya)
- wine_servings (konsumsi anggur yang dinyatakan dalam gelas)
- pure_alcohol (konsumsi alkohol murni yang dinyataksan dalam liter, nama variabel ini sudah penulis singkat)
Adapun deskripsi yang ditampilkan adalah :
Untuk menampilkan informasi struktur dataset dapat menggunakan fungsi info() dari pandas.
Data diambil dari https://catalog.data.gov/dataset/alzheimers-disease-and-healthy-aging-data/
#!/usr/bin/env python3
import pandas as pd
data = pd.read_csv("Alzheimer_s_Disease_and_Healthy_Aging_Data.csv")
print(data.info())
Outputnya
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 178539 entries, 0 to 178538
Data columns (total 39 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 RowId 178539 non-null object
1 YearStart 178539 non-null int64
2 YearEnd 178539 non-null int64
3 LocationAbbr 178539 non-null object
4 LocationDesc 178539 non-null object
5 Datasource 178539 non-null object
6 Class 178539 non-null object
7 Topic 178539 non-null object
8 Question 178539 non-null object
9 Response 0 non-null float64
10 Data_Value_Unit 178539 non-null object
11 DataValueTypeID 178539 non-null object
12 Data_Value_Type 178539 non-null object
13 Data_Value 120885 non-null float64
14 Data_Value_Alt 0 non-null float64
15 Data_Value_Footnote_Symbol 70619 non-null object
16 Data_Value_Footnote 70619 non-null object
17 Low_Confidence_Limit 120750 non-null float64
18 High_Confidence_Limit 120750 non-null float64
19 Sample_Size 0 non-null float64
20 StratificationCategory1 178539 non-null object
21 Stratification1 178539 non-null object
22 StratificationCategory2 178539 non-null object
23 Stratification2 178539 non-null object
24 StratificationCategory3 0 non-null float64
25 Stratification3 0 non-null float64
26 Geolocation 159375 non-null object
27 ClassID 178539 non-null object
28 TopicID 178539 non-null object
29 QuestionID 178539 non-null object
30 ResponseID 0 non-null float64
31 LocationID 178539 non-null int64
32 StratificationCategoryID1 178539 non-null object
33 StratificationID1 178539 non-null object
34 StratificationCategoryID2 178539 non-null object
35 StratificationID2 178539 non-null object
36 StratificationCategoryID3 0 non-null float64
37 StratificationID3 0 non-null float64
38 Report 0 non-null float64
dtypes: float64(12), int64(3), object(24)
memory usage: 53.1+ MB
Dari output tersebut dapat diketahui antara lain:
Untuk mengetahui dimensi atau jumlah baris dan kolom dataset dapat menggunakan shape dari pandas. Data diambil dari https://catalog.data.gov/dataset/alzheimers-disease-and-healthy-aging-data/
import pandas as pd
data = pd.read_csv("Alzheimer_s_Disease_and_Healthy_Aging_Data.csv")
print(data.shape)
Output:
(178539, 39)
Dari output tersebut diketahui dataset mempunyai 178539 baris dan 39 kolom.
Untuk menampilkan data baris terakhir dengan python dapat menggunakan fungsi tail() dari pandas. Tuliskan banyaknya baris yang akan ditampilkan (n) dalam tanda kurung. Kalau n tidak ditulis maka secara default n=5.
Data diambil dari https://catalog.data.gov/dataset/alzheimers-disease-and-healthy-aging-data/
import pandas as pd
data = pd.read_csv("Alzheimer_s_Disease_and_Healthy_Aging_Data.csv")
print(data.tail(7))
Output :
RowId ... Report
178532 2019~2019~9004~Q41~AGE~AGE_OVERALL~RACE~NAA ... NaN
178533 2019~2019~9002~Q41~AGE~AGE_OVERALL~GENDER~MALE ... NaN
178534 2019~2019~9002~Q42~AGE~5064~RACE~HIS ... NaN
178535 2019~2019~9003~Q42~AGE~65PLUS~RACE~ASN ... NaN
178536 2019~2019~9002~Q42~AGE~65PLUS~RACE~HIS ... NaN
178537 2019~2019~9003~Q42~AGE~5064~RACE~BLK ... NaN
178538 2019~2019~9004~Q42~AGE~5064~RACE~NAA ... NaN
[7 rows x 39 columns]
Dari output tersebut juga dapat diperoleh informasi jumlah baris dan kolomnya yaitu 178539 baris dan 39 kolom.
Untuk menampilkan data baris pertama dengan python dapat menggunakan fungsi head() dari pandas. Tuliskan banyaknya baris yang akan ditampilkan (n) dalam tanda kurung. Kalau n tidak ditulis maka secara default n=5.
Data diambil dari https://catalog.data.gov/dataset/alzheimers-disease-and-healthy-aging-data/
import pandas as pd
data = pd.read_csv("Alzheimer_s_Disease_and_Healthy_Aging_Data.csv")
print(data.head())
Output :
RowId ... Report
0 2016~2016~12~Q27~AGE~AGE_OVERALL~GENDER~MALE ... NaN
1 2015~2015~66~Q43~AGE~5064~GENDER~MALE ... NaN
2 2018~2018~66~Q18~AGE~5064~GENDER~MALE ... NaN
3 2018~2018~66~Q34~AGE~5064~GENDER~FEMALE ... NaN
4 2015~2015~16~Q43~AGE~65PLUS~GENDER~FEMALE ... NaN
[5 rows x 39 columns]
Dari output tersebut juga dapat diperoleh informasi jumlah kolomnya, yaitu 39 yang tidak semua kolom ditampilkan.
Misalkan ada dataset dalam format csv. Data tersebut dapat di-load atau diimpor dengan python dengan library pandas. Berikut script untuk load file data.csv.
import pandas as pd
data = pd.read_csv("data.csv")
Beberapa library atau module python yang sering digunakan untuk statistika adalah
- numpy: digunakan untuk melakukan analisa data numerik dan perhitungan berbasis vektor atau matriks
- pandas: digunakan untuk melakukan pengolahan data tabular
matplotlib: digunakan untuk melakukan ploting atau penggambaran grafik, dapat digunakan sebagai alat bantu dalam analisa data
- statsmodels: digunakan untuk melakukan uji hipotesa, eksplorasi data maupun pemodelan statistika
- scipy: digunakan untuk melakukan uji statistika, juga dapat digunakan untuk melakukan pemodelan statistika
File csv merupakan file yang umum digunakan sebagai file data. Mudah dalam pembuatannya. Begitu juga dengan aksesnya. Bisa dibuat dengan text editor, spreadsheet software maupun statistical software. Pada kesempatan kali ini tidak menggunakan statistical software seperti R.
Membuat file csv dengan text editor
Prinsip pembuatan adalah :
- Antar kolom dipisahkan oleh tanda koma (,)
- Kolom pertama (umumnya) sebagai header atau nama/judul kolom
- Antar baris dipisahkan oleh enter
- Angka dituliskan seperti biasanya
- Teks/string dituliskan dalam tanda kutip (" atatu ‘)
Contoh, data kasus malaria tahun 2019 terdiri atas 2 kolom, yaitu provinsi dan jumlah.
Dispersi atau ukuran penyebaran data menunjukkan seberapa bervariasi suatu data.
Kali ini data yang digunakan diambil dari dataset ldeaths yang merupakan bagian dari UKLungDeaths. Dataset UKLungDeaths berisi data jumlah kematian akibat penyakit bronchitis, emphysema dan asma di Inggris dalam kurun waktu 1974-1979. Data ini disajikan berdasarkan bulan dan jenis kelamin. Secara total untuk kedua jenis kelamin ada di ldeaths, laki-laki mdeaths dan perempuan fdeaths.
Nilai minimal
Nilai maksimal
Range
range(ldeaths)
[1] 1300 3891
Varians
var(ldeaths)
[1] 371911.8
Standar deviasi
Data yang digunakan :
> nilai
[1] 25 60 79 32 57 74 52 70 82 36 75 77 81 95 41 65 92 85 55 66 52 10 64 75 78
[26] 25 80 98 81 67 41 71 83 54 64 72 88 62 74 45 60 78 89 76 48 84 84 90 15 79
[51] 35 67 17 82 69 74 63 80 85 61
Mean
> mean(nilai)
[1] 65.31667
Rerata nilai adalah 65,31667.
Cara 2 : menggunakan quantile()
Karena median tak lain adalah kuartil 2 atau dengan kata lain posisinya di tengah-tengah atau pada posisi 50% maka
> quantile(nilai, 0.5)
50%
70.5
Median nilai adalah 70,5.
Modus
> names(which.max(table(nilai)))
[1] "74"
Modus adalah 74.
Kuartil 1
> quantile(nilai, 0.25)
25%
54.75
Kuartil 1 nya adalah 54,75.
Input data dalam R sangat mudah dan ada beragam cara, yaitu:
- Menuliskan dalam bentuk syntax. Data diinput sebagai vektor. Penulis lebih suka menggunakan cara ini apabila data tersebut 1 variabel saja dan banyaknya tidak lebih dari 30. Kadang juga penulis gunakan untuk data yang banyaknya kurang dari 100
- Melalui data frame. Data diinput ke dalam bentuk tabel. Baris tabel menunjukkan kasus sedangkan kolomnya adalah variabel. Cocok digunakan apabila lebih dari 1 variabel.
- Import dari file. Data dibuat tanpa menggunakan R dan disimpan ke dalam bentuk file. Data bisa dibuat menggunakan text editor (contoh vim, gvim, nano, pico, kate), aplikasi perkantoran (LibreOffice Calc dan Microsoft Excel) atau aplikasi statistik lainnya seperti SPSS, Minitab, dan Stata).
Pada kesempatan ini yang digunakan adalah cara pertama. Misalkan datanya adalah nilai ujian dari 60 mahasiswa sebagai berikut :