Machine learning belakangan ini semakin populer. Salah satu yang bisa dilakukan dengan machine learning adalah klasifikasi. Ada beberapa metode klasifikasi. Kali ini akan melakukan klasifikasi dengan cara decision tree supervised learning.
Skenario klasifikasi yang akan kita lakukan adalah menentukan jenis (label) bunga iris berdasarkan kriteria (atribut) yang diberikan. Jenis bunga irisnya adalah iris setosa, iris versicolor dan iris virginica. Adapun kriterianya berdasarkan panjang sepal, lebar sepal, panjang petal dan lebar petal.
Berikut adalah script python sederhana untuk menampilkan isi direktori aktif
#!/usr/bin/python
import os
isidirektori = os.listdir()
for i in range(len(isidirektori)):
print(isidirektori[i])
Uji normalitas data dapat dilakukan dengan beberapa cara antara lain
- Visual dengan grafik salah satunya histogram
- Uji statistik seperti Kolmogorov-Smirnov atau Shapiro-Wilk
Berikut akan dilakukan uji normalitas atas data konsumsi bir tahun 2010. Data diambil dari https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv dengan pengubahan nama variabel menjadi lebih singkat.
Uji normalitas dengan histogram
Histogramnya
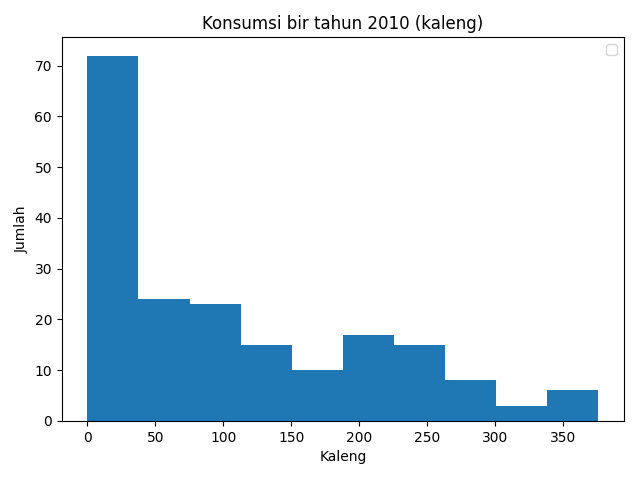
Dari histogram tersebut tampak dengan jelas bahwa histogram tidak simetris dengan skewness positif. Maka dapat disimpulkan data konsumsi bir ini tidak mengikuti distribusi normal.
Untuk membuat histogram dengan python dibutuhkan library pandas dan matplotlib dengan fungsi .hist() dan rangkaiannya seperti contoh histogram konsumsi bir berikut:
#!/usr/bin/python3
import pandas as pd
import matplotlib.pyplot as plt
# sumber data https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv
# dengan editing header variabel
alkohol = pd.read_csv("../dataset/drinks.csv")
# histogram
plt.hist(x='beer_servings', data=alkohol)
plt.xlabel('Kaleng')
plt.ylabel('Jumlah')
plt.title('Konsumsi bir tahun 2010 (kaleng)')
plt.tight_layout()
plt.show()
Hasilnya:
Catatan sebelumnya tentang bagaimana membuat data secara acak dengan python, kali ini hampir sama. Bedanya, data yang dibuat berasal dari distribusi Gaussian (distribusi normal).
Akan dibuat data dengan besar sampel 200, mean 165, standar deviasi 12.5.
#!/usr/bin/python3
import numpy as np
sampel = 200
rerata = 165
deviasi = 12.5
data = np.random.normal(rerata, deviasi, sampel)
print(data)
Hasilnya
[169.9036172 158.13190825 156.9590178 167.74827264 168.62534857
171.69140206 161.65434678 187.34374928 150.29836841 152.49471216
160.69172875 173.22405024 171.53443046 159.89375268 170.59784794
158.46572357 168.20110897 131.00882242 169.37660362 172.71471591
162.34684852 159.31860527 156.87505418 152.25881337 173.94068172
134.98130158 146.94872437 159.80322766 176.60094913 173.111627
166.68329084 161.23836143 170.69908908 152.20927403 159.85371294
160.92108223 174.01411013 145.55719871 179.99900982 180.02266499
152.10976505 164.51292664 157.8864326 170.85776142 160.73666817
174.51669873 149.72123539 164.06125902 165.84558021 170.64970455
173.35880599 153.86472607 186.08708782 163.16383892 168.79688713
161.76180346 159.76044878 152.08482654 170.20465648 175.60900504
162.92716486 177.19471848 171.2871681 144.971927 164.3188071
162.15660742 180.74130005 160.39323975 139.65007794 157.81802319
156.85566358 166.50332995 177.2953798 158.30680384 177.13544237
164.38845426 179.17517071 175.87660328 179.5223744 161.40472123
174.16465527 168.58063922 159.48342785 190.17379458 168.96513379
171.72529799 155.25957095 183.97047167 157.56975133 188.34529069
170.38858718 143.31405164 185.9190679 169.51101188 155.36181972
144.61623691 181.3892726 163.22218044 134.37177323 154.19044256
160.45700363 142.59563772 160.37605357 171.44273535 169.70640078
153.59534214 152.29849613 177.73804824 162.62462227 196.5989286
162.765947 155.38582305 177.19867532 177.71711759 167.58320205
172.24747986 165.12620889 176.47353528 187.94811592 172.89502868
158.11438788 181.9815273 194.18043935 166.29368658 171.40764381
178.04726676 142.06688725 159.72220239 168.75140017 171.79149347
158.87557205 155.78707993 161.47244798 153.4709923 147.64848437
170.51523267 173.77590858 178.25774495 140.32563393 162.97639238
163.90251236 184.85207452 176.66444031 180.65892624 163.03595927
151.77083121 179.13141898 171.70632128 169.38558184 172.38264989
157.08041456 155.24917828 184.10916072 168.50840784 174.18864833
163.74798374 158.54818729 183.45911273 159.49934259 162.99057938
167.15176222 152.19491374 165.46079737 157.79831857 149.42032516
178.66081158 171.26776676 178.47832146 183.10797135 141.55075244
163.33402213 177.31821748 168.56905941 188.02853802 163.44916488
168.17361967 179.70875574 156.75504417 160.78535928 149.1140051
172.12819615 173.66107973 162.21543281 173.87079486 161.03824355
175.80570369 162.87110577 161.26534934 143.54189568 175.43542171
164.21584719 164.01339793 151.90799391 168.24579668 169.70043163
164.26476352 170.30071889 162.32963983 172.41727919 156.12259096]
Secara default data yang dihasilkan bertipe float. Apabila menghendaki data integer bisa tambahkan .astype(int)
Bingung membuat data? Gampang, python dengan library numpy punya solusinya!
Akan dibuat data acak bertipe integer (bilangan bulat). Banyaknya data 200, nilai minimal 145, maksimal 180.
#!/usr/bin/python3
import numpy as np
data = np.random.randint(size=200, low=145, high=180)
print(data)
Berikut datanya
[160 147 160 177 147 149 170 149 166 153 154 156 160 165 161 154 168 173
151 145 158 148 163 178 164 166 159 159 172 147 153 170 174 159 152 170
151 159 168 167 147 156 177 168 176 151 153 146 163 156 149 145 152 173
151 162 165 164 179 173 168 172 158 177 148 177 157 150 145 164 171 166
175 164 159 158 178 173 155 162 178 171 146 145 158 151 150 151 165 166
148 168 159 175 165 173 167 178 150 173 147 161 175 158 150 150 159 168
172 159 160 165 156 150 170 175 171 174 149 175 165 168 155 179 161 162
160 146 151 172 171 179 157 171 170 157 149 147 169 151 172 148 164 169
160 158 168 163 153 154 179 163 174 172 176 166 172 166 173 179 155 158
176 151 152 157 164 175 164 165 179 177 175 164 162 164 172 152 172 154
179 162 171 162 149 149 154 163 168 163 178 179 166 166 167 156 158 155
171 148]
Misalkan akan dicari berapa median konsumsi alkohol perkapita? Jawabannya bisa diketahui dengan menggunakan fungsi describe() atau median() yang dimiliki pandas.
#!/usr/bin/env python3
import pandas as pd
# sumber data https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv
# dengan editing header variabel
data = pd.read_csv("../dataset/drinks.csv")
# median
print('median konsumsi bir adalah ',data['beer_servings'].median(),'kaleng')
print('median konsumsi spirit adalah ', data['spirit_servings'].median())
print('median konsumsi anggur adalah ', data['wine_servings'].median(), 'gelas')
print('median konsumsi alkohol murni adalah ', data['pure_alcohol'].median(), 'liter')
Misalkan akan dicari berapa rerata konsumsi alkohol perkapita? Jawabannya bisa diketahui dengan menggunakan fungsi describe() atau mean() yang dimiliki pandas.
#!/usr/bin/env python3
import pandas as pd
# sumber data https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv
# dengan editing header variabel
data = pd.read_csv("../dataset/drinks.csv")
# mean
print('rerata konsumsi bir adalah ',data['beer_servings'].mean(),'kaleng')
print('rerata konsumsi spirit adalah ', data['spirit_servings'].mean())
print('rerata konsumsi anggur adalah ', data['wine_servings'].mean(), 'gelas')
print('rerata konsumsi alkohol murni adalah ', data['pure_alcohol'].mean(), 'liter')
Untuk menampilkan statistik deskriptif suatu data, bisa menggunakan fungsi describe() dari library yang dimiliki python yaitu pandas.
Berikut ini akan ditampilkan deskripsi data konsumsi alkohol dunia. Sumber data : https://github.com/fivethirtyeight/data/blob/master/alcohol-consumption/drinks.csv
Data tersebut memuat konsumsi alkohol perkapita dari 193 negara. Ada 4 variabel yaitu :
- beer_servings (konsumsi bir yang dinyatakan dalam kaleng)
- spirit_servings (konsumsi minuman beralkohol spirit; maaf, variabel ini masih belum penulis pahami sepenuhnya)
- wine_servings (konsumsi anggur yang dinyatakan dalam gelas)
- pure_alcohol (konsumsi alkohol murni yang dinyataksan dalam liter, nama variabel ini sudah penulis singkat)
Adapun deskripsi yang ditampilkan adalah :
Untuk menampilkan informasi struktur dataset dapat menggunakan fungsi info() dari pandas.
Data diambil dari https://catalog.data.gov/dataset/alzheimers-disease-and-healthy-aging-data/
#!/usr/bin/env python3
import pandas as pd
data = pd.read_csv("Alzheimer_s_Disease_and_Healthy_Aging_Data.csv")
print(data.info())
Outputnya
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 178539 entries, 0 to 178538
Data columns (total 39 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 RowId 178539 non-null object
1 YearStart 178539 non-null int64
2 YearEnd 178539 non-null int64
3 LocationAbbr 178539 non-null object
4 LocationDesc 178539 non-null object
5 Datasource 178539 non-null object
6 Class 178539 non-null object
7 Topic 178539 non-null object
8 Question 178539 non-null object
9 Response 0 non-null float64
10 Data_Value_Unit 178539 non-null object
11 DataValueTypeID 178539 non-null object
12 Data_Value_Type 178539 non-null object
13 Data_Value 120885 non-null float64
14 Data_Value_Alt 0 non-null float64
15 Data_Value_Footnote_Symbol 70619 non-null object
16 Data_Value_Footnote 70619 non-null object
17 Low_Confidence_Limit 120750 non-null float64
18 High_Confidence_Limit 120750 non-null float64
19 Sample_Size 0 non-null float64
20 StratificationCategory1 178539 non-null object
21 Stratification1 178539 non-null object
22 StratificationCategory2 178539 non-null object
23 Stratification2 178539 non-null object
24 StratificationCategory3 0 non-null float64
25 Stratification3 0 non-null float64
26 Geolocation 159375 non-null object
27 ClassID 178539 non-null object
28 TopicID 178539 non-null object
29 QuestionID 178539 non-null object
30 ResponseID 0 non-null float64
31 LocationID 178539 non-null int64
32 StratificationCategoryID1 178539 non-null object
33 StratificationID1 178539 non-null object
34 StratificationCategoryID2 178539 non-null object
35 StratificationID2 178539 non-null object
36 StratificationCategoryID3 0 non-null float64
37 StratificationID3 0 non-null float64
38 Report 0 non-null float64
dtypes: float64(12), int64(3), object(24)
memory usage: 53.1+ MB
Dari output tersebut dapat diketahui antara lain:
Untuk mengetahui dimensi atau jumlah baris dan kolom dataset dapat menggunakan shape dari pandas. Data diambil dari https://catalog.data.gov/dataset/alzheimers-disease-and-healthy-aging-data/
import pandas as pd
data = pd.read_csv("Alzheimer_s_Disease_and_Healthy_Aging_Data.csv")
print(data.shape)
Output:
(178539, 39)
Dari output tersebut diketahui dataset mempunyai 178539 baris dan 39 kolom.
Untuk menampilkan data baris terakhir dengan python dapat menggunakan fungsi tail() dari pandas. Tuliskan banyaknya baris yang akan ditampilkan (n) dalam tanda kurung. Kalau n tidak ditulis maka secara default n=5.
Data diambil dari https://catalog.data.gov/dataset/alzheimers-disease-and-healthy-aging-data/
import pandas as pd
data = pd.read_csv("Alzheimer_s_Disease_and_Healthy_Aging_Data.csv")
print(data.tail(7))
Output :
RowId ... Report
178532 2019~2019~9004~Q41~AGE~AGE_OVERALL~RACE~NAA ... NaN
178533 2019~2019~9002~Q41~AGE~AGE_OVERALL~GENDER~MALE ... NaN
178534 2019~2019~9002~Q42~AGE~5064~RACE~HIS ... NaN
178535 2019~2019~9003~Q42~AGE~65PLUS~RACE~ASN ... NaN
178536 2019~2019~9002~Q42~AGE~65PLUS~RACE~HIS ... NaN
178537 2019~2019~9003~Q42~AGE~5064~RACE~BLK ... NaN
178538 2019~2019~9004~Q42~AGE~5064~RACE~NAA ... NaN
[7 rows x 39 columns]
Dari output tersebut juga dapat diperoleh informasi jumlah baris dan kolomnya yaitu 178539 baris dan 39 kolom.
Untuk menampilkan data baris pertama dengan python dapat menggunakan fungsi head() dari pandas. Tuliskan banyaknya baris yang akan ditampilkan (n) dalam tanda kurung. Kalau n tidak ditulis maka secara default n=5.
Data diambil dari https://catalog.data.gov/dataset/alzheimers-disease-and-healthy-aging-data/
import pandas as pd
data = pd.read_csv("Alzheimer_s_Disease_and_Healthy_Aging_Data.csv")
print(data.head())
Output :
RowId ... Report
0 2016~2016~12~Q27~AGE~AGE_OVERALL~GENDER~MALE ... NaN
1 2015~2015~66~Q43~AGE~5064~GENDER~MALE ... NaN
2 2018~2018~66~Q18~AGE~5064~GENDER~MALE ... NaN
3 2018~2018~66~Q34~AGE~5064~GENDER~FEMALE ... NaN
4 2015~2015~16~Q43~AGE~65PLUS~GENDER~FEMALE ... NaN
[5 rows x 39 columns]
Dari output tersebut juga dapat diperoleh informasi jumlah kolomnya, yaitu 39 yang tidak semua kolom ditampilkan.
Misalkan ada dataset dalam format csv. Data tersebut dapat di-load atau diimpor dengan python dengan library pandas. Berikut script untuk load file data.csv.
import pandas as pd
data = pd.read_csv("data.csv")
Beberapa library atau module python yang sering digunakan untuk statistika adalah
- numpy: digunakan untuk melakukan analisa data numerik dan perhitungan berbasis vektor atau matriks
- pandas: digunakan untuk melakukan pengolahan data tabular
matplotlib: digunakan untuk melakukan ploting atau penggambaran grafik, dapat digunakan sebagai alat bantu dalam analisa data
- statsmodels: digunakan untuk melakukan uji hipotesa, eksplorasi data maupun pemodelan statistika
- scipy: digunakan untuk melakukan uji statistika, juga dapat digunakan untuk melakukan pemodelan statistika
Dengan adanya library, programmer python dimudahkan. Lebih efisien. Contoh : untuk mencari nilai akar kuadrat, tidak perlu menuliskan bertele-tele menuliskan rumus. Tinggal impor dan gunakan fungsi yang ada saja Misalkan akan mencari nilai akar kuadrat dari 100.
import math
print(math.sqrt(100))
Baris 1, deklarasi untuk mengimpor library. Nama library-nya math.
Baris 2, fungsi print() untuk menampilkan ke layar. sqrt() adalah fungsi untuk mencari nilai akar kuadrat. Karena fungsi ini ada di library atau modul math, maka dituliskan juga librarynya.
Comments atau komentar adalah sekumpulan teks yang dituliskan dalam program tetapi tidak akan dieksekusi. Ada 2 jenis comments dalam bahasa python, yaitu
- Single line comment. Hanya terdiri dari 1 baris comments. Untuk menuliskannya, beri tanda # di awal comments.
Contoh :
# ini adalah single line comment
- Multiline comments. Terdiri dari lebih dari 1 baris. Dibuka dan ditutup dengan '''
Contoh :
'''
ini adalah program python
untuk mengetahui sesuatu
'''
Python memiliki beberapa tipe data, yaitu :
- None
- Numeric
- Boolean
- Sequence
- Set
- Map
Tipe data python none
Hanya memiliki 1 nilai yaitu None
Tipe data numeric
Tipe data numeric terdiri atas tipe data integer dan float. Integer merupakan bilangan bulat. Float merupakan bilangan desimal.
Tipe data boolean
Terdiri dari 2 nilai yaitu True dan False
Tipe data sequence
Ada 3 macam yaitu string, list dan tuple
Tipe data string
Data ini diapit oleh ' atau ". Contoh :
Dalam bahasa python, ada 4 ketentuan pemberian nama variabel, yaitu :
- Harus dimulai dengan huruf (a-z, A-Z) atau garis bawah underscore (_) dan tidak boleh diawali dengan angka (0-9).
- Boleh mengandung karakter huruf, angka dan underscore (a-z, A-Z, 0-9, _)
- Bersifat sensitive case yang mengartikan bahwa variabel Nama, nama dan NAMA adalah variabel yang berbeda
- Tidak boleh menggunakan reserved words seperti for, while, return
Apa itu python
Python adalah bahasa pemrograman yang diciptakan oleh Guido van Rossum. Python bersifat open source sehingga semua orang boleh menggunakan dan mengembangkannya. Bahasa pemrograman satu ini tidak spesifik untuk keperluan tertentu, tetapi umum. Python bisa digunakan untuk membuat aplikasi desktop, database, web, data science, machine learning, dll.
Apakah python cocok untuk data science? Mengapa?
Ya. Karena python open source maka semua orang boleh mengembangkannya, termasuk untuk keperluan data science. Contohnya adalah pembuatan library numpy, scipy, pandas, scikit-learn, matplotlib, seaborn, dll.
Setelah [upgrade slackbuilds]({% post_url 2016-07-03-upgrade-slackbuilds %}) kemarin ternyata Virtual Machine Manager tidak bisa dijalankan.
$ virt-manager
Traceback (most recent call last):
File "/usr/share/virt-manager/virt-manager", line 33, in <module>
from virtinst import util as util
File "/usr/share/virt-manager/virtinst/__init__.py", line 89, in <module>
from virtinst.distroinstaller import DistroInstaller
File "/usr/share/virt-manager/virtinst/distroinstaller.py", line 23, in <module>
from . import urlfetcher
File "/usr/share/virt-manager/virtinst/urlfetcher.py", line 34, in <module>
import requests
ImportError: No module named requests
Ternyata, ada masalah dependensi. ImportError: No module named requests menunjukkan tidak adanya modul requests, atau tidak terinstall paket python-requests. Ini dibuktikan dengan output ls /var/log/packages|grep python-request yang kosong.
Saat melakukan pencarian dengan pip, muncul pesan
/usr/lib64/python2.7/site-packages/pip/_vendor/requests/packages/urllib3/util/ssl_.py:315: SNIMissingWarning: An HTTPS request has been made, but the SNI (Subject Name Indication) extension to TLS is not available on this platform. This may cause the server to present an incorrect TLS certificate, which can cause validation failures. For more information, see https://urllib3.readthedocs.org/en/latest/security.html#snimissingwarning.
SNIMissingWarning
/usr/lib64/python2.7/site-packages/pip/_vendor/requests/packages/urllib3/util/ssl_.py:120: InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. For more information, see https://urllib3.readthedocs.org/en/latest/security.html#insecureplatformwarning.
InsecurePlatformWarning
Biar peringatan ini tidak muncul lagi, ndg-httpsclient harus diupgrade.
gdrv adalah command line tool berbasis python untuk Google Drive. Cara menginstallnya
pip install gdrv
GooglePlayDownloader adalah aplikasi berantar muka grafis (GUI) untuk mengunduh berkas APK dari Google Play Store. Dependensi:
- python-protobuf (>=2.4)
- python-requests (>=0.12)
- python-ndg-httpsclient
- python-pyasn1
- python-wxgtk2.8 (>=2.8)
- python 2.5+
- java (opsional)
Itu yang tertulis di README.txt nya GooglePlayDownloader, tapi ternyata, khusus python-wxgtk2.8 diganti saja dengan wxpython. Oke kita install dependensinya dulu (pastikan tersambung internet).
easy_install protobuf requests ndg-httpsclient
Nah, karena wxpython diinstall dengan easy_install ga berhasil, maka install saja pakai [slackbuildnya]({% post_url 2015-07-18-install-wxpython %}).
Kemudian, unduh Google Play Downloadernya. Sebenarnya sih mau unduh dulu atau install dependensi dulu terserah. Sebenarnya ada .deb nya, tapi berhubung di sini pakai Slackware maka unduh aja kode sumbernya biar lebih asyik.
wxPython adalah salah satu toolkit untuk membuat aplikasi grafis dengan python. Untuk menginstallnya mudah, kita install saja slackbuildnya. Pastikan tersambung internet.
wget http://slackbuilds.org/slackbuilds/14.1/libraries/wxPython.tar.gz
tar xzf wxPython.tar.gz
cd wxPython
wget http://downloads.sourceforge.net/wxpython/wxPython-src-2.8.12.1.tar.bz2
sh wxPython.SlackBuild
installpkg /tmp/wxPython-2.8.12.1-x86_64-2_SBo.tgz
Pip akan memudahkan kita semua untuk menginstall paket-paket yang terkait dengan python.
wget --no-check-certificate https://bootstrap.pypa.io/get-pip.py
python get-pip.py